
Fast Healthcare Interoperability (FHIR) Standard
Fast Healthcare Interoperability Resources (FHIR) is a modern standard for sharing healthcare data. It uses RESTful APIs and JSON to enable easy exchange of patient information between different systems, enhancing interoperability and facilitating better access to and utilization of health data across diverse healthcare platforms.
FHIR defines a set of resources (such as patients, practitioners, medications, etc.) and standardizes the way these resources are structured and exchanged, promoting consistency and compatibility between different healthcare applications and systems. This standardization enhances the ability to access and use health data for various purposes, including patient care, research, analytics, and more.
Snowflake Native App Framework
Our unique solution leverages Snowflake’s capabilities for efficient data transformation and management using the Snowflake Streamlit native application. It incorporates Kipi’s developed Snowpark-based JSON flattener for dynamic flattening of FHIR REST response data.
Additionally, it adheres to HL7 FHIR 4.0 standards, utilizing metadata-driven ingestion and transformation, supporting intelligent delta loading, FHIR standards-based data modeling, and the creation of the FHIR Bundle.
This 360-degree solution provides insights into patient demographics, treatment effectiveness, and risk factors. This enables healthcare professionals to proactively act and improve patient outcomes.
FHIR Data App: High-Level Architecture
Introduction
In this application, we adhere to HL7 FHIR Standards, ensuring interoperability and standardized data exchange in healthcare systems. We Leveraged the robust infrastructure of the HAPI FHIR Server. While implementing this solution, healthcare organizations can effortlessly substitute this server with their own FHIR-compliant server.
Furthermore, the versatility of our application extends to its ability to interface with multiple servers concurrently. This unique capability enables comprehensive access to disparate data sources, facilitating a holistic view of patient information while ensuring accuracy and timeliness in healthcare delivery.
Data Flow
While retrieving data from the FHIR Server to establish a connection, we utilize MetaSchema Rest Endpoints to pull FHIR entities. These entities encompass various data, including patient medical and demographic information, wellness data, patient providers, payors, and appointments, all formatted in JSON. In addition, bundle files are handled, and the data is queried and processed directly from an S3 bucket. This allows for efficient management and access to the FHIR data stored in the bundles, providing seamless integration with the data retrieval process.
Subsequently, this data is stored in our staging layer within the Snowflake environment. We employ a delta-loading approach, uploading the latest records. Once this initial process concludes, our Snowflake dynamic flattener is employed to flatten the data before ingestion into the core layer.
From there, the data progresses to the consumption layer built on a base-modeled EDW layer, which serves as the foundation for developing persona-based BI Dashboards in Streamlit.
Architectural Details
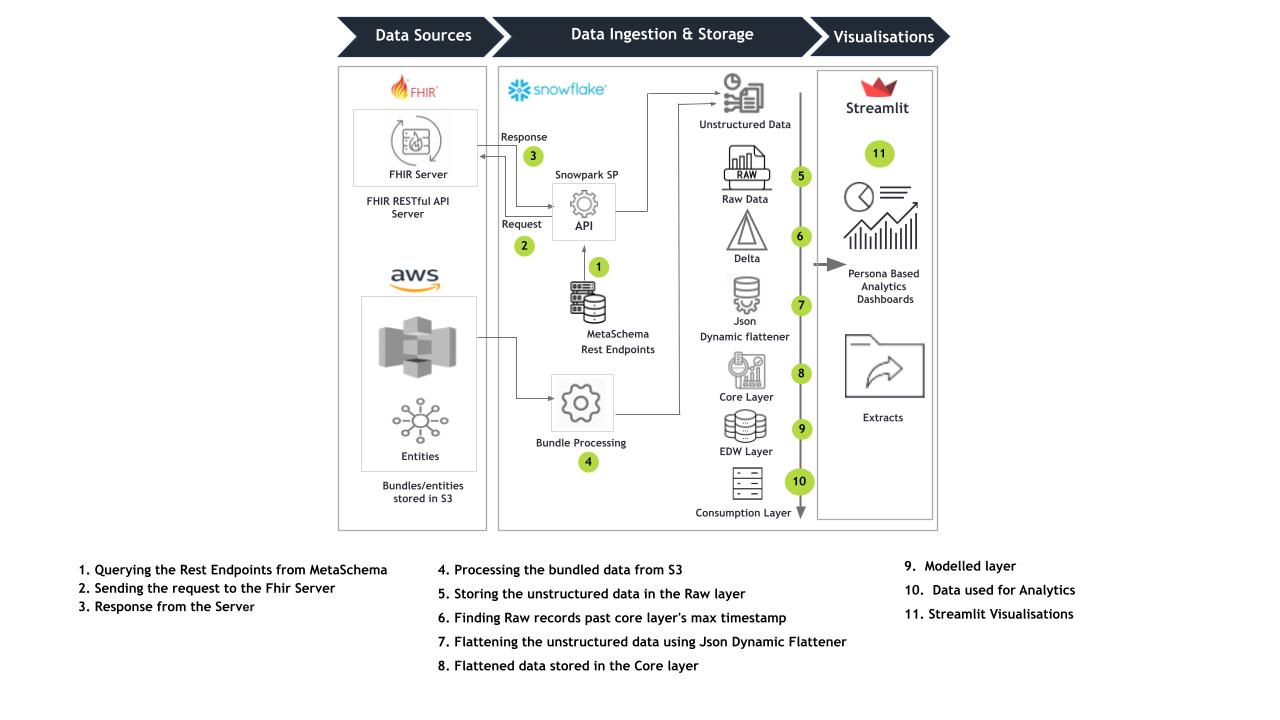
The endpoint can be configured in the network rule and is passed to the ‘fetch’ stored procedure. During the data retrieval process, we utilize the endpoint in conjunction with the entity name queried from the master table, forming a URL like: f”https://{ENDPOINT}/baseR4/{entity}?”
Architectural Considerations
- Only one endpoint possible
- Only default authentication method supported
- The modeled layer should be configured to align with our current requirements. Presently, it has been modeled for 17 FHIR entities.
- In Streamlit visualizations, we can only display 16 MB of data.
Deployment
We’re deploying our application on the Snowflake Marketplace for open customers. Additionally, we offer an internal package exclusively for Kipi Customers, providing customization options and early access benefits.
Tools Involved
- Snowflake
- Streamlit in Snowflake
- Snowpark (Python)
- AWS
Implementation Details
Go to the objects tab.
Step 1: Creating Objects
The application is available on the Snowflake marketplace. Once installed, users need to go to the Objects tab. With a single click, users will be able to create all the listed objects below. Additionally, it inserts standard FHIR JSON templates into the master table within the Meta schema.
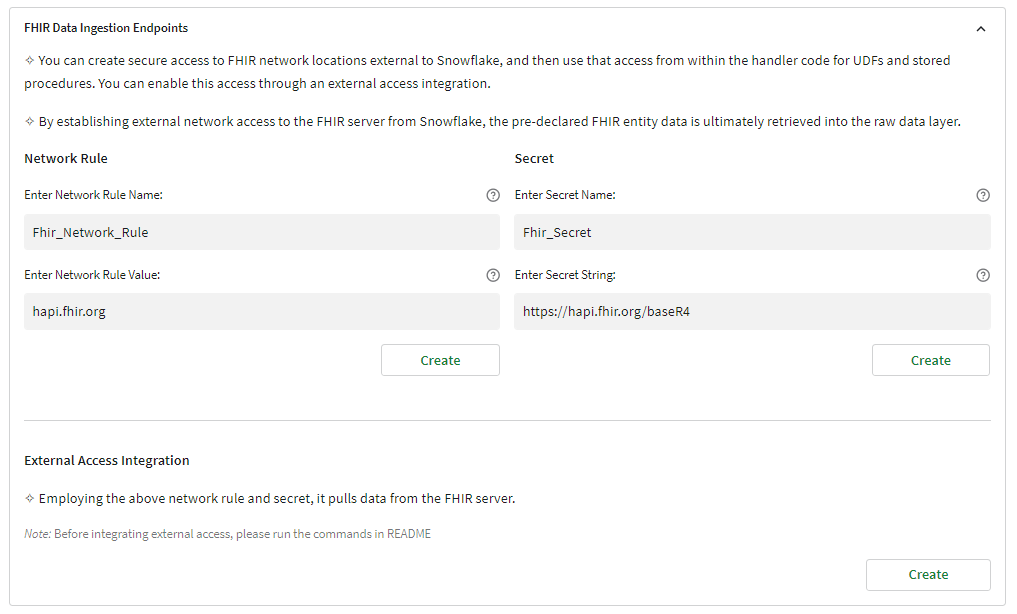
Step 2: Create Network rule, Secret key and External API Integration
(If data resides in FHIR Server)
Creating the network rule, secret and these two will be used in the External API Integration which helps in fetching the data from the FHIR server.
Network rule represents external network location and restriction for access. It also specifies identifiers such as host name, direct communication with the network.
Secrets represents credentials required to authenticate with external rules and secrets.
The endpoint is stored within the ‘ENDPOINT’ table when establishing the network rule. Subsequently, this stored endpoint is retrieved through a query within the stored procedure, and it becomes an integral part of the URL used in the data retrieval process.
Step 3: Create an External Stage
(If the data resides in an S3 bucket, and it is in the form of bundles.)
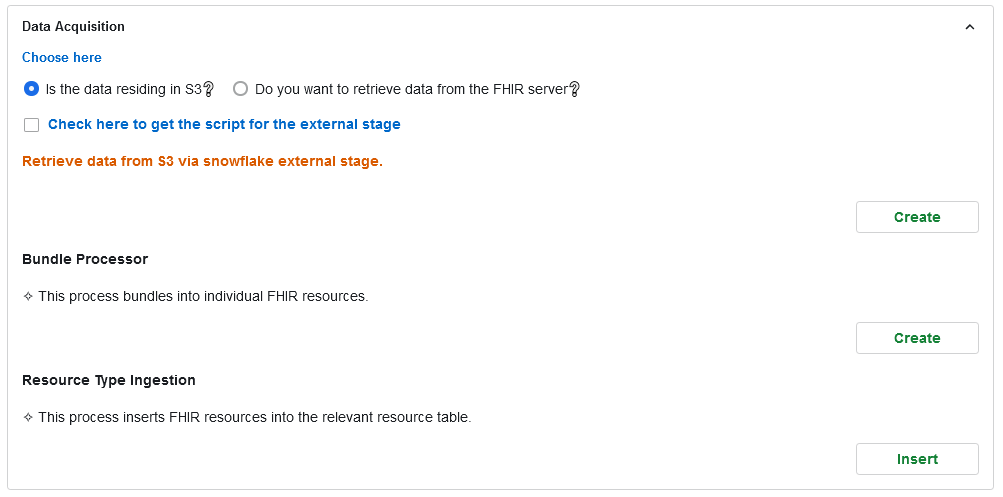
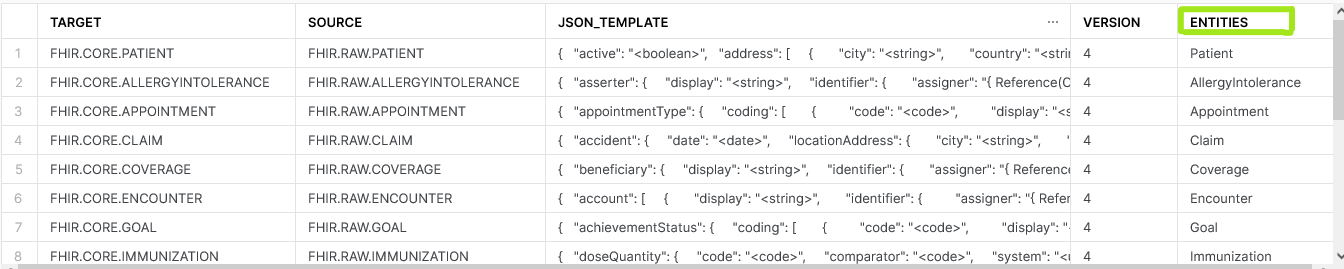
Step 4: Involves the optional tasks of modifying the existing JSON template and adding new FHIR resource templates
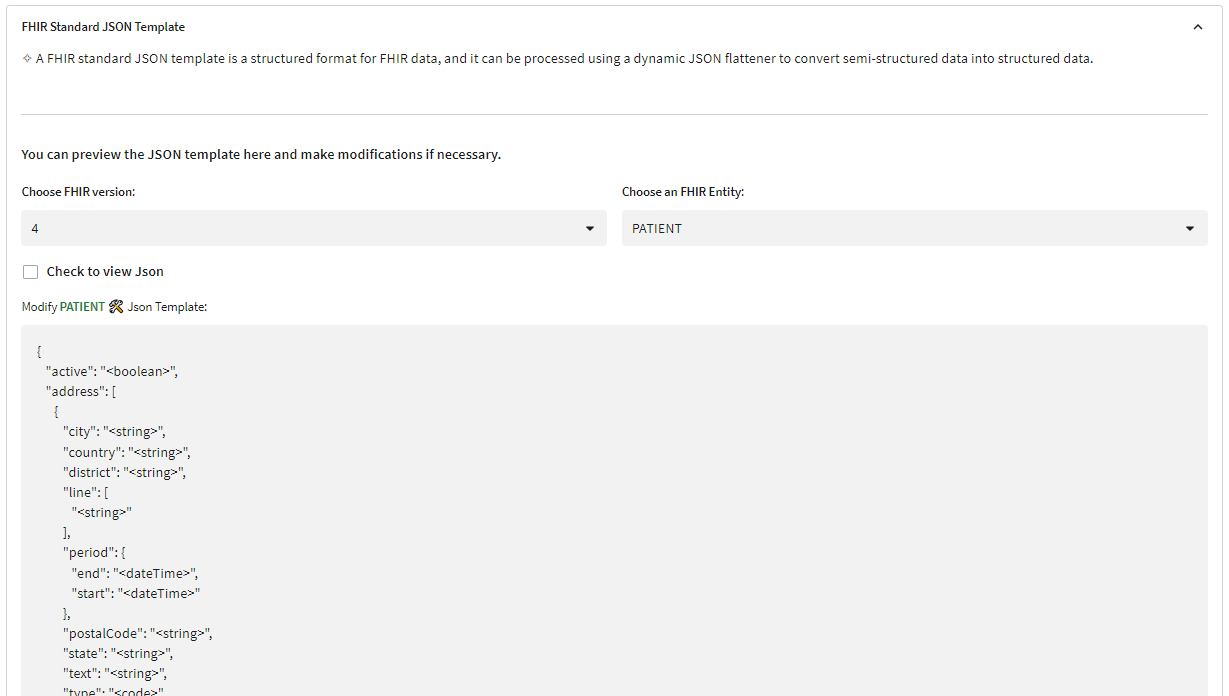
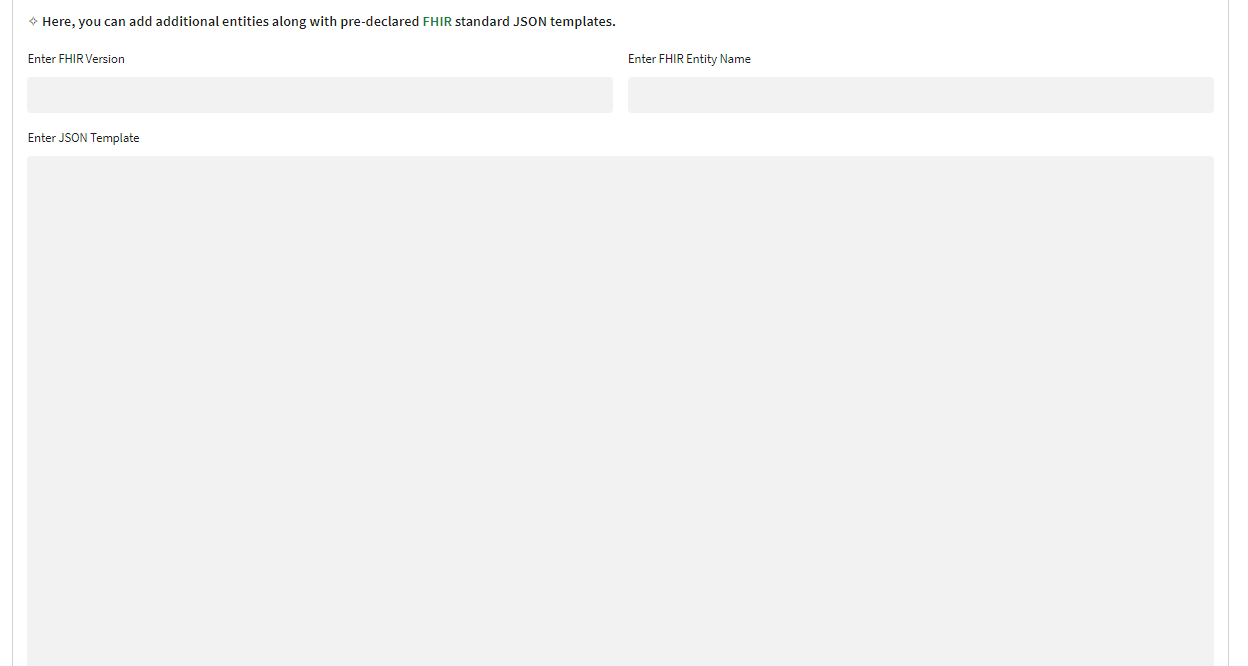
List of existing JSON templates:
- AllergyIntolerance
- Appointment
- Claim
- Coverage
- Encounter
- ExplanationOfBenefit
- Goal
- Immunization
- Medication
- NutritionOrder
- Observation
- Organization
- Patient
- Practitioner
- Practitionerrole
- Procedure
- MedicationStatement
Step 5: Create Dynamic Json Flattener Stored Procedure
Create the procedure by clicking on create

Step 6: Create EDW and Consumption layers
Create the procedures for EDW and Consumption layers

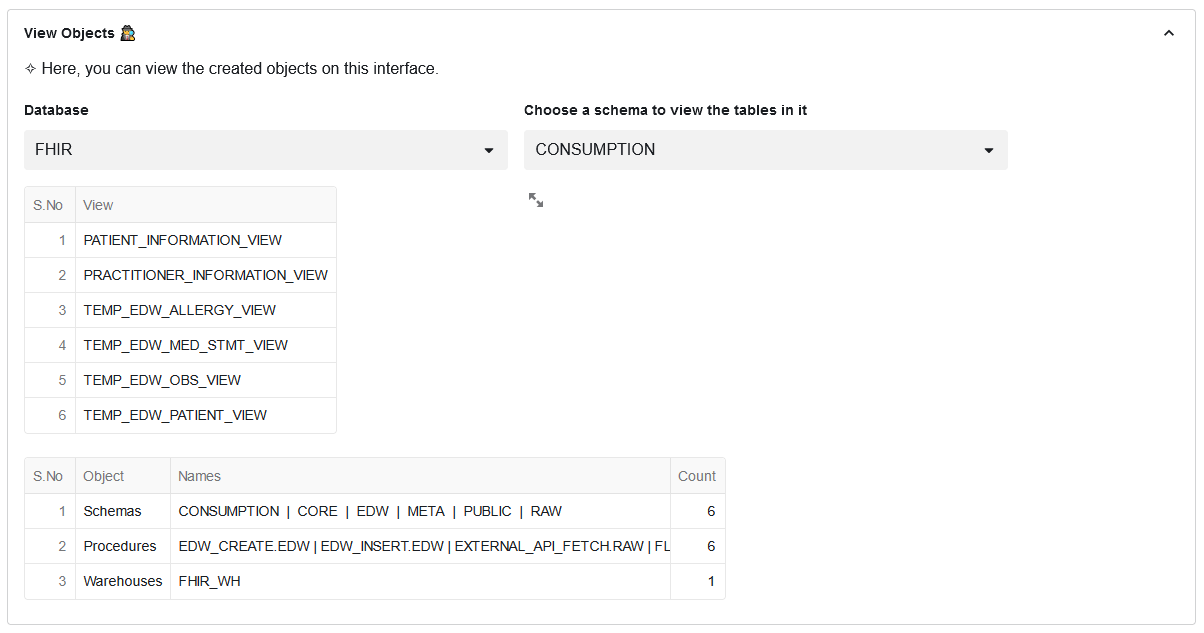
Step 7: In this section view all the created objects
Go to the Schedule tab
Step 8: Scheduling the stored procedures
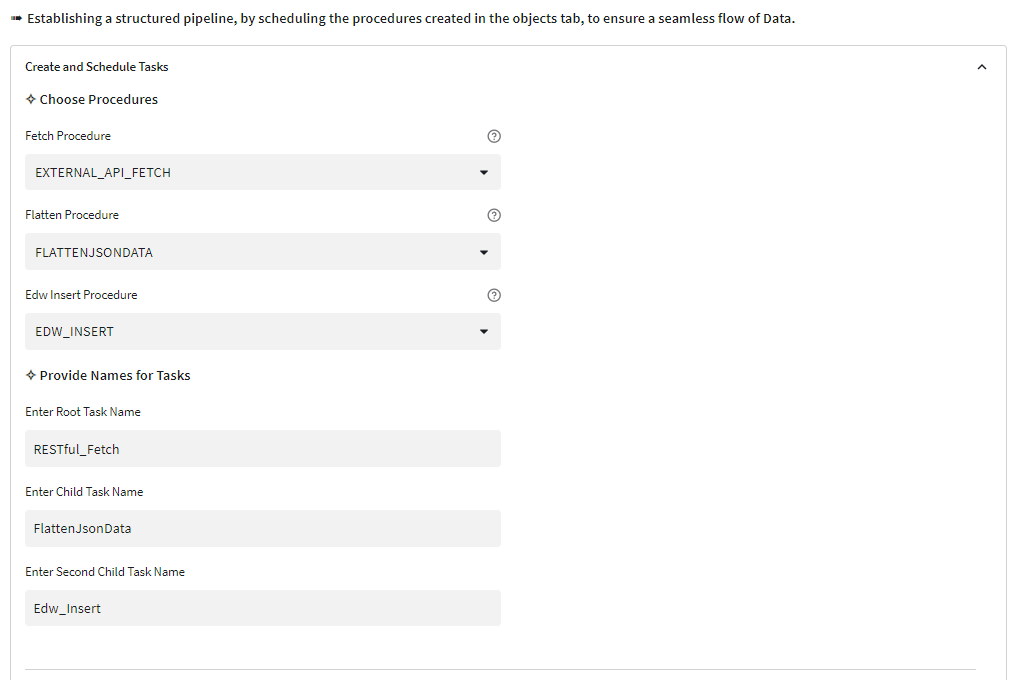
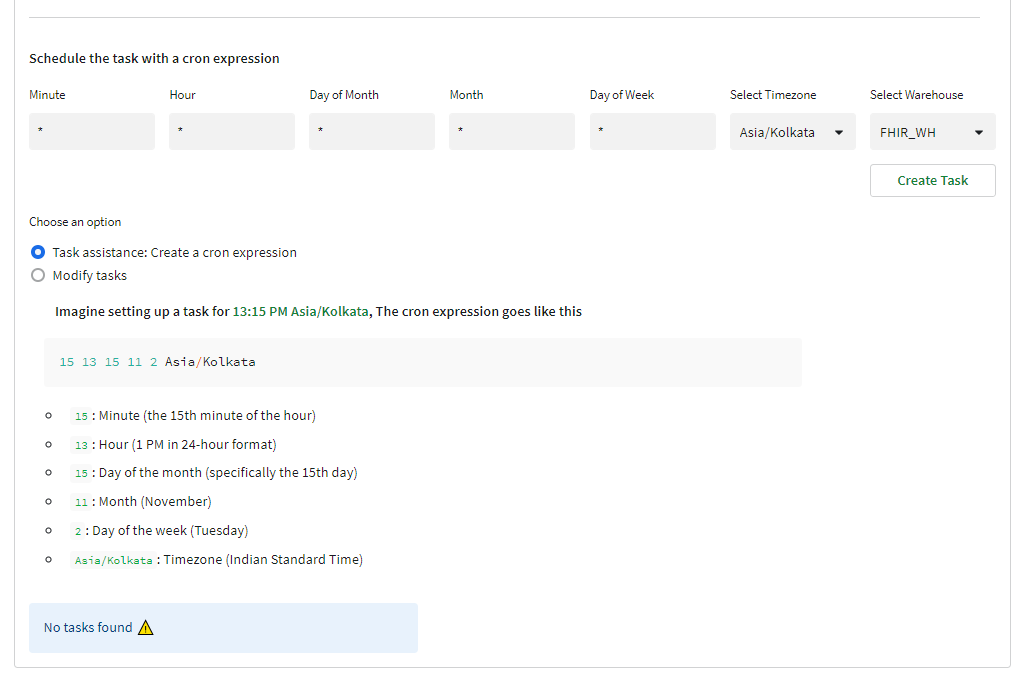
Step 9: Visualizations for three different personas Patient, Practitioner, Payor
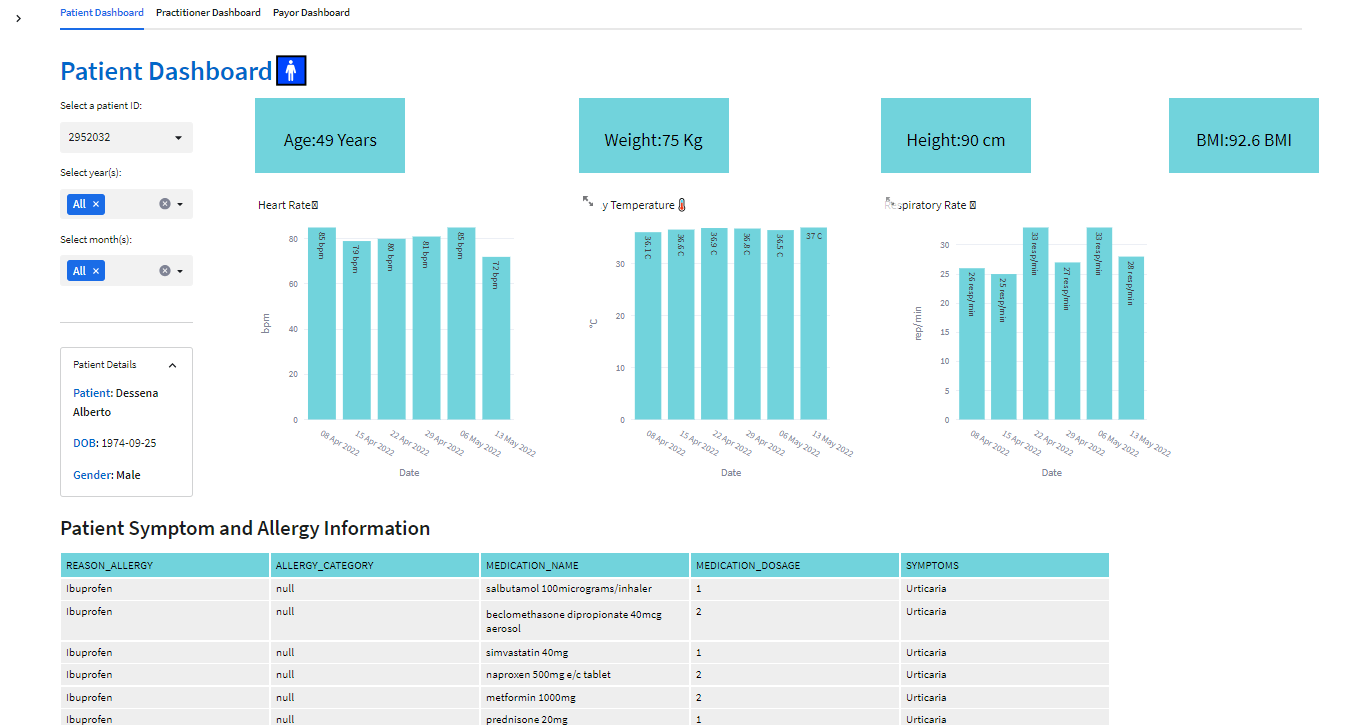


Key Features:
- MetaSchema Rest Endpoints: Utilizing MetaSchema Rest Endpoints, our solution offers seamless connectivity to the FHIR Server, enabling healthcare organizations to retrieve a wide array of healthcare data, including patient demographics, medical records, appointments, and more.
- Efficient Bundle File Handling: We streamline the handling of bundle files, allowing for efficient querying and processing of data directly from an S3 bucket. This approach ensures smooth management and access to FHIR data stored within bundles, enhancing the integration process.
- Delta-Loading Approach: Our solution adopts a delta-loading approach for storing FHIR data in the Snowflake environment. By focusing on uploading only the latest records, we ensure data currency and accuracy, minimizing redundancy and optimizing storage resources.
- Snowflake Dynamic Flattener: With our Snowflake dynamic flattener, we simplify the process of flattening FHIR data before ingestion into the core layer. This tool enhances data readability and accessibility, making it easier for healthcare professionals to analyze and derive insights from the data.
- Base-Modeled EDW Layer: The consumption layer built on a base-modeled Enterprise Data Warehouse (EDW) serves as the foundation for developing persona-based BI Dashboards. This layer enables healthcare professionals to access actionable insights and analytics tailored to their specific needs and roles.
- Streamlined Deployment and Management: The KIPI.BI Native app simplifies the deployment and management of the FHIR Server within Snowflake environments. With guided steps and intuitive interfaces, healthcare organizations can effortlessly deploy and manage their FHIR infrastructure, ensuring seamless integration and efficient healthcare data interoperability.
- Customizable BI Dashboards: Our solution empowers healthcare organizations to develop customizable BI Dashboards tailored to their specific requirements and workflows. With persona-based analytics, healthcare professionals can access relevant insights and make data-driven decisions to improve patient care and operational efficiency.





