
Authored by – Pavan Kumar Undamattla and Panga Karthik
Introduction
In today’s data-driven landscape, managing JSON data efficiently poses a significant challenge for organizations worldwide. As data structures evolve and schemas change, extracting precise information becomes increasingly complex. However, with the emergence of Kipi Data Utils Dynamic JSON Flattener for Snowflake, a revolutionary solution has arrived, promising to streamline JSON data management effortlessly. Let’s delve into the challenges faced by data professionals and the comprehensive solutions offered by this innovative tool.
Challenges
Dynamic Schema Changes: One of the primary hurdles in managing JSON data is coping with dynamic schema changes. As data structures evolve over time, traditional flattening processes often struggle to adapt, leading to data integrity issues and inefficiencies in data extraction.
Data Extraction Precision: Extracting specific data elements from nested JSON structures poses another significant challenge. Conventional methods lack the flexibility to customize data extraction, resulting in cumbersome processes and inaccurate results.
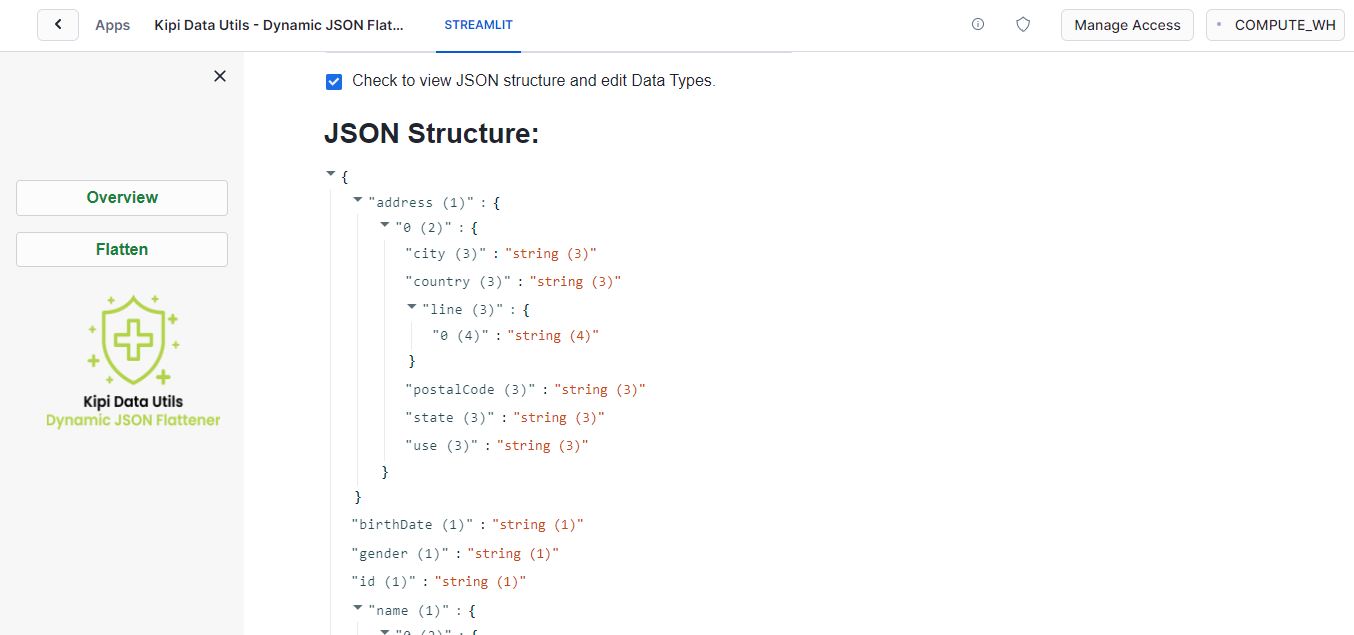
JSON Structure Analysis: Analyzing the nested levels and data types of JSON keys presents a challenge for data professionals. Without a clear understanding of the JSON structure and its data types, extracting precise information becomes challenging, leading to errors in data analysis.
Version Control and Data Consistency: Maintaining version control and ensuring data consistency across different iterations is vital for reliable data management. However, traditional approaches often lack robust versioning mechanisms, making it challenging to track changes and roll back to previous versions when necessary.
Solutions
Schema Adaptability: Kipi Data Utils Dynamic JSON Flattener for Snowflake addresses the challenge of dynamic schema changes by dynamically adjusting to evolving data structures. Regardless of how the JSON schema evolves, the tool ensures seamless flattening processes while maintaining data integrity and reliability.
Customized Data Extraction: This tool allows users to extract specific fields from JSON data during the flattening process. Users can precisely select data elements for analysis, reporting, or other purposes, enhancing efficiency and accuracy in data handling.
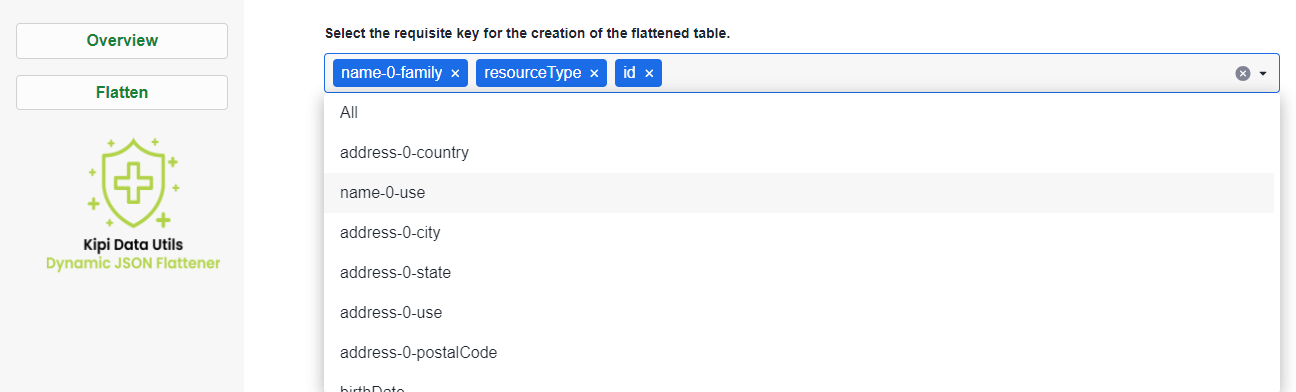
JSON Structure Analysis: The tool empowers users with deep insights into JSON structure, including nested levels and data types of keys. This capability ensures a thorough understanding of the JSON schema, facilitating precise data extraction and informed decision-making.
Version Control and Rollback Capability: The tool offers built-in version control and rollback capabilities, empowering users to maintain complete control over their data versions. Tracking changes and enabling easy rollback to older versions if needed ensures data consistency and reliability throughout the flattening process.

Conclusion
In conclusion, Kipi.bi marks a significant milestone in simplifying JSON data management by addressing the key challenges faced by data professionals and offering comprehensive solutions. With Kipi.bi, organizations unlock unparalleled efficiency, enabling them to harness the full potential of their JSON data effortlessly.





